Создал отдельную тему про как устроить словарь под неоднозначные сопоставления Задача. Поиск сложного в сложном.
Распознавание рукописного текста
Сообщений 91 страница 120 из 165
Поделиться912009-08-16 21:34:38
- Активный участник

- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Поделиться922009-08-19 01:53:06
- Активный участник

- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Собственно мой первый распознаватель рукописных печатных символов! За качество распознавания прошу сильно не бить, это всего-лишь игрушка.
Как работает программа.
При запуске открывается окно с белым квадратом - на нём можно рисовать. Можно загрузить символ из файла (кнопка "Open picture"). Кнопка "Reload" перезагружает файл или стирает картинку если файл изначально не был загружен.
После нажатия на кнопку "Do it" выполняется следующий алгоритм.
1. "Включается" взаимодействие между всеми точками буквы по типу притяжения.
2. Программа отслеживает момент скелетизации буквы и останавливает притяжение.
Типичная картина изменения плотности изображения буквы при притяжении выглядит так: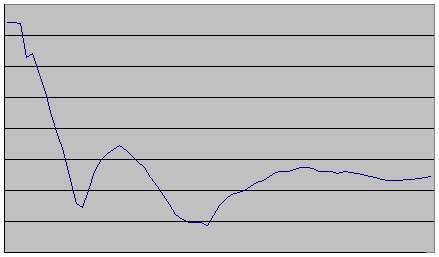
Первый существенный минимум - это скелетизация. Второй минимум - это сжатие в точку. Неудивительно, что буква сжимается в точку за два этапа. Интенсивность взаимодействия между более близкими точками больше, чем между более дальними. Поэтому процессы локального сжатия опережают процессы глобального сжатия.
Программа ищет минимум в диапазоне 6 последовательных замеров плотности. Справа в окошке можно видеть как меняется плоность буквы (первое число) и разность между текущей и предыдущей плотностью (второе число).
Конечно, есть более быстрые алгоритмы скелетизации, но здесь важно соблюсти чистоту идеологии - всё должно быть построено на едином принципе - взаимодействие, связь, движение.
3. Максимально скелетизированная буква отрисовавается и все её точки подвергаются взаимодействию типа "отталкивание".
4. Отталкиванию препятствует окружность, которая проведена из центра масс буквы до самого дальнего пиксела буквы. Можно видеть как точки "оседают" на этой окружности.
5. После того как остановится последняя точка, программа делит окружность на 100 секторов и подсчитывает число точек попавших в каждый сектор.
6. После этого программа последовательно сравнивает данное распределение плотности по окружности с 33 эталонами, поворачивая его на 3,6°. Для каждого эталона запоминается минимальное отличие и угол, при котором оно было обнаружено.
Эталоны были созданы по такому же принципу - просто однократным применением алгоритма к символам, которые лично я посчитал идеальными 
7. В окошке справа выводятся отсортированные сверху-вниз результаты распознавания. После буквы следует мера похожести (чем число меньше, тем больше буквы похожи) и угол на котором был получен минимум отличия.
Выводы.
1. Качество распознавания слабенькое из-за того, что скелетированная буква при разлёте испытывает накапливающееся влияние неоднородностей, что вызывает "эффект бабочки".
2. Использование эталонов - это не совсем честный приём. Желательно, чтобы программа сама строила классы изображений. Но для этого, имхо, нужно чтобы она делала это в процессе обучения, а не пытаясь разделить на классы полученное множество признаков. В идеале я вижу это так:
- есть некий базовый класс
- есть мера допустимого различия между классами
- есть первый образ. Первый образ всегда относится к первому классу.
- другие классы для поступающих образов создаются при превышении допустимого различия между ними и первым классом. Такой мерой может быть что-то вроде устойчивости класса.
3. Данный тип распознавания - это своего рода сравнение значений хэш-функций. Многие изображения могут давать одинаковую плотность распределения на окружности, но для некоторых букв оно даёт достаточную меру различия. Если посмотреть как сортируются буквы при распознавании, видно что они сортируются, в общем-то, по похожести между собой.
4. Замечено, что если буква распознана неправильно, то угол, определённый для верной буквы, обычно соответствует нарисованному. Это можно использовать для улучшения качества, если допустить, что правильно ориентированные буквы более вероятны.
Поделиться932009-08-19 02:07:24
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Букву Т распознает лучше всего, особенно когда она перевернута
Для других букв наверно тоже есть какие-то особо чувствительные к ним функции.
Еще нарисовал А короткими черточками, точками не дает. Оно зависло на этапе сжатия. В другой раз остановилось, но когда уже сжало все в комок.
Отредактировано NO (2009-08-19 02:10:42)
Поделиться942009-08-19 02:09:40
- Активный участник

- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
Prosolver написал(а):
Желательно, чтобы программа сама строила классы изображений.
т.е. в процессе разпознавания определяла алфавит, язык, пол и возраст пишущего... шучу...
Поделиться952009-08-19 02:58:05
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
NO написал(а):
Букву Т распознает лучше всего, особенно когда она перевернута
Букву Р, тоже неплохо. А вообще правильные буквы, как правило, оказываются в верхних строчках. Удивило, что буква О распознаётся хуже всех.
NO написал(а):
Для других букв наверно тоже есть какие-то особо чувствительные к ним функции
Возможно, но я считаю важным использовать единый принцип. Здесь по сути используется способ проекции двумерных символов на одномерную последовательность. Почему-то всегда так получается, что сравнивать что-то между собой можно только в одномерном пространстве, последовательно.
NO написал(а):
зависло на этапе сжатия
Поправил всякое - должно помочь.
Поделиться962009-08-19 03:17:44
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
При проекциях всегда разные фигуры сливаются в одну. Это способ выделения признака, а не всего распознавания. Для распознавания может быть удобно наоборот перевести в более многомерное пространство, если там классы будут разделяться проще, типа прямыми плоскостями. Для 32 букв было бы удобно 5-мерное пространство, по 1 биту на размерность, где все буквы расположены по вершинам 5-мерного куба.
Поделиться972009-08-19 04:30:16
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
NO написал(а):
Для 32 букв было бы удобно 5-мерное пространство
надо больше, фактически, разные начертания одной и той же буквы - это разные буквы для распознавателя...
кроме этого, не все признаки будут ортогональны... это нужно будет отдельно выяснять...
лучше с запасом взять 8-12 мерное пространство...
Поделиться982009-08-19 13:50:42
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Egg написал(а):
в процессе разпознавания определяла алфавит, язык, пол и возраст пишущего
А почему бы и нет. Чтобы в процессе обучения строились всякие дополнительные полезные классы, типа: мужчина/женщина, пессимист/оптимист. Если человек это делает играючи, почему бы не сделать это возможным и для машины. Тем более это может дополнять контекст и упрощать дальнейшие действия по распознаванию. Я не дополняю ТЗ, просто размышляю.
NO написал(а):
Для 32 букв было бы удобно 5-мерное пространство
Egg написал(а):
лучше с запасом взять 8-12 мерное пространство...
Насколько я понимаю идею классификации, распознавание не может обойтись одним пространством (хоть и многомерным). Сам процесс распознавания - это процесс перемещения ("протискивания") исходного изображения через несколько классифицирующих пространств. Более менее всё понятно с первым и последним пространством. Первое пространство состоит только из двух классов-аттракторов - чёрный цвет и белый цвет. Все точки изображения классифицируются в этом пространсстве. Последнее пространство состоит из 33 классов-аттракторов (если речь идёт только, например, о заглавных буквах). Самое интересное, сколько промежуточных (и сколько-мерных) пространств надо ещё ввести между ними. На GotAI будет (я надеюсь) активно прорабатываться идея нескольких последовательных пространств: белые/чёрные точки -> линии, дуги, уголки -> траектории написания -> буквы.
Или вы говорите о некоем универсальном классифицирующем пространстве, в котором машина сама сможет создавать подпространства и подклассы, необходимые для достаточно качественного распознавания?
Поделиться992009-08-19 13:55:22
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Чем больше тем лучше. Там наверно и про пол с возрастом будут признаки. "Старый Ш", молодое "У"
Поделиться1002009-08-19 15:04:00
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Первое пространство это 32*32 точки, или сколько там было по ТЗ, оно 1024-мерное если бы цвета пикселей были совсем независимы. Если предположить что движение ручки непрерывно, это будет линия, длиной скажем 40 пикселей, если повороты контролируются с точностью 10 градусов то всего 36, 5 бит на поворот, на букву в две петельки 72 поворота и следовательно 72 прямых, ошибок штуки 3 и особенностей почерка 20, длина прямой 20 размеров. Итого 72*((72+3+20)*20) видов букв, или кодируемых 72*12 битами. 800 вместо 1024 бит. Это если было бы можно восстановить траекторию ручки. Все равно много, это модель броуновского рисования. Нас из этих 1000 интересуют только 5 бит. В начале все независимо, никаких правил или намерений насчет этого участка листа не известно, поэтому очень многомерное пространство.
Всего функций 1000->5 может быть 32^1000 = 2^5000. Значит средняя функция распознавания должна быть длиной 1 килобайт, ну или килобайт коэффициентов нейросети или еще чего такого, при максимальной упаковке. А при создании нужно принять 5000 решений. Лучше это дело поручить компьютеру, нужно чего-то само-обучающееся делать.
Поделиться1012009-08-19 15:19:40
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Я свои тетрадки посмотрел. Четко пишу только заголовки, чтобы обозначить тему. И разные перечисления, в которых никаких закономерностей нет. Остальное если пишу для себя вообще какое-то брынь-брынь, чего-то как-то обозначил, пострашнее, чтобы потом побыстрее вспомнилось что имел ввиду. Такое читается только по словам, когда тема ясна, а вот тема по буквам. Все что можно вообще рисую картинками.
Поделиться1022009-08-19 15:42:38
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Prosolver:
Можно сделать два круга, вернее по времени снимать показания два раза. Так уже 4 буквы распознается.
Поделиться1032009-08-19 16:38:58
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
NO написал(а):
нужно чего-то само-обучающееся делать
Конечно. Я был уверен, что другие варианты даже не рассматриваются.
NO написал(а):
чего-то как-то обозначил, пострашнее, чтобы потом побыстрее вспомнилось что имел ввиду
Это всё интересно. Но по моему это уже несколько другая задача. Я предлагаю пока пользоваться таким критерием: "не требовать от машины того, чего не делает человек".
Кроме тебя вряд ли кто распознает эту тетрадку (у самого такие же есть). Потому, что ты создал свой алфавит, свои слова и обозначения, вроде рукописи Bойнича. Я бывает распознаю написанное только используя критерии из собственной памяти, типа: это я писал чёрной пастой, потому что это было в гостях, поэтому эта закорючка - слово "шахматы". Компьютер не может использовать чужую память для выявления признаков для классификации.
NO написал(а):
Можно сделать два круга, вернее по времени снимать показания два раза. Так уже 4 буквы распознается.
Там можно много ещё чего сделать, например:
- считать плотность буквы по направлениям без рассеивания, просто подсчитывая кол-во точек из центра масс в 100 (или больше) секторах;
- рассеивать букву через отталкивание от центра масс - пробовал, получается прикольно;
- учитывать разную вероятность углов поворота (правильно ориентированные буквы полагать более вероятными);
- использовать общую статистическую информацию (например, как подсказал Slava, сравнивать буквы по временнОй динамике сжатия (см. график));
- сравнивать полученное распределение плотностей не сразу с эталоном посекторно, а доработать его так, чтобы пики лучше совпадали.
Но данный распознаватель я развивать дальше не планирую, это был просто экперимент.
Поделиться1042009-08-19 17:40:54
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Я так и понял, что у тебя какая-то необычная процедура и ты ее хочешь попробовать на какой-то задаче.
Будем называть это преобразованием Просолвера может где-то пригодится. Что хорошего она может вроде понятно, а проблемы не очень. Теоретически для распознавания топологий нужно все переводить в показательное множество следующего порядка, а тут в том же, да еще разменость понижается. Это просто один признак, а не распознавание.
Но задача вцелом любопытная, там много чего можно применить и нужно придумать. Я буду думать об этом. Только рутины разной много, не хочется за нее браться пока не остаются проблемы. Пока застопорилось на эффективном выяснении эквавалентности двух регэкспов, или двух hmm-сетей, или грамматик. Хотелось бы это делать на уровне рассуждений, без перебора вариантов.
Поделиться1052009-08-19 18:03:24
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
NO написал(а):
у тебя какая-то необычная процедура и ты ее хочешь попробовать на какой-то задаче
Процедура очень обычная и масимально простая - исходные объекты задачи (сначала точки или прямоугольники) постоянно обмениваются в бесконечном цикле друг с другом квантами через Эвклидово пространство по кратчайшему пути. Квант - это "сведения" о том, как нужно поменять направление движения при получении кванта и его отдаче.
Процедуру эту хочу попробовать на всех задачах, в частности, на задаче распознавания рукописного текста. Например, у меня есть подозрение, что любую классификацию, в физическом смысле, можно смоделировать притяжением и отталкиванием (передачей соответствующих квантов). Это вполне очевидная идея.
NO написал(а):
для распознавания топологий нужно все переводить в показательное множество следующего порядка, а тут в том же, да еще разменость понижается. Это просто один признак, а не распознавание
Тут надо смотреть глубже. Прямая линия или уголок буквы можно представить как множество точек, которые связаны определённым взаимодействием. Любая буква, в нашем восприятии обладает определённой устойчивостью - буквально, в физическом смысле. Т.е. мы можем сказать "уголки жёсткие", "линии гибкие", "буква наклонилась" и т.д. Используя такую физическую аналогию я собираюсь подобрать и смоделировать такие взаимодействия, чтобы буквы при, буквально, ударе разламывались на объекты из "множества следующего порядка" - например, уголки, линии (или что-то другое). А потом можно дальше играться с этими объектами (опять же, в физической интерпретации), уже игнорируя тот факт, что они состоят из точек.
Поделиться1062009-08-19 21:02:36
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
Prosolver написал(а):
Прямая линия или уголок буквы можно представить как множество точек, которые связаны определённым взаимодействием.
если псевдофизика, которую ты накладываешь на буквы определена геометрией,
(а именно так ты ее определяешь), то в конце всевозможных преобразований
именно геометрические отличия по максимуму ты и получишь...
Поделиться1072009-08-19 22:53:51
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Egg написал(а):
именно геометрические отличия по максимуму ты и получишь
И этого достаточно.
Поделиться1082009-08-19 22:59:55
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
Prosolver написал(а):
И этого достаточно.
для чего? для того, чтобы выяснить, что Т, М, Ш, ИЛ и прочая
могут писаться СОВЕРШЕННО ОДИНАКОВО геометрически?
Поделиться1092009-08-19 23:15:18
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Egg написал(а):
для чего?
Для координации.
Зачем вообще что-либо распознавать? Чтобы в соответствии с результатом распознавания что-то сделать - т.е. создать некое геотметрическое отличие. Одно геометрическое отличие (результат распознавания) обуславливает другое геометрическое отличие (некое действие). Например, чисто геометрическая надпись "Закрыто", обуславливает чисто геометрическую фигуру разворота на месте.
Egg написал(а):
Т, М, Ш, ИЛ и прочая
могут писаться СОВЕРШЕННО ОДИНАКОВО геометрически?
Этого совсем не понял. Буквы Т и М пишутся геометрически совершенно разно. (Или это был "камень" скоординированный в направлении моей игрушки? )
Поделиться1102009-08-19 23:22:55
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
долго объяснять - сам увидишь...
суть скажу...
1) если два исходных изображения одинаковы, распознать их невозможно...
2) "геометрическая" подзадача состоит в том, чтобы выявить различающие признаки...
если это понятно, остальное приложится...
Поделиться1112009-08-20 21:55:14
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Продолжаю эксперименты по геометрической псевдофизике
Дальнейшее направление исследований заключается в моделировании целостности и её разрушении. В качестве простейшей модели целостной системы был написан макет, моделирующий поведение двух связанных точек в пустом пространстве - кодовое имя макета "стальной лом в космосе". Точкам (шарикам) при запуске сообщается случайный импульс, с краями экрана - упругое соударение.
Макет разворачивается в full screen, для выхода - клик мышью.
Числа вверху отображают сверху-вниз, соответственно, расстояние между точками и суммарную энергию системы.
Модель с двумя шариками демонстрирует прелюбопытное свойство - эта примитивная система аккумулирует кинетическую энергию!
При соударении со стенкой, система из шариков иногда резко (и интуитивно непонятно) тормозит. Сначала я думал, что это глюк алгоритма. Потом проанализировав детали понял, что два шарика (как целостная система) при соударении со стенкой могут переводить свою кинетическую энергию движения в пространстве - в кинетическую энергию локализованого взаимодействия. Причём таких локализованных взаимодействий может быть 2 вида: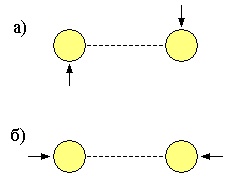
шарики (как целостная система) стоят на месте (относительно экрана), при этом
а) вращаются вокруг центра связи
б) совершают колебательное движение около центра связи
Чтобы для наглядности усилить этот эффект переписал макет (качать здесь). Теперь это уже не "стальной лом в космосе", а скорее "каучуковая палочка в космосе".
Наглядно видно, что при торможении системы в целом (относительно экрана), движение никуда не исчезает, а переходит во вращательное и/или колебательное движение частей системы относительно центра связи. И наоборот, чтобы система начала быстро перемещаться относительно экрана необходимо, чтобы колебательное и вращательное движение шариков перешло в движение всей системы.
Поделиться1122009-08-20 22:52:48
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
Prosolver написал(а):
Продолжаю эксперименты
по-прежнему не очень понятно к чему это всё...
про кинетическую энергию можно прочитать здесь: http://ru.wikipedia.org/wiki/ Кинетическая_энергия
Поделиться1132009-08-20 23:54:22
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Egg написал(а):
не очень понятно к чему это всё...
Egg написал(а):
"геометрическая" подзадача состоит в том, чтобы выявить различающие признаки...
Когда к инженеру приходят с просьбой написать программу, распознающую что-либо (например, центр ладони), он изучает ТЗ, выявляет полезные признаки, которые могут быть предметом классификации. Потом, используя свои умения, знания, навыки - пишет код. Дальше работает машина. В этой методологической цепочке есть одно подозрительное звено - инженер. Я хочу, чтобы задачу инженера по выявлению признаков (и прочим его действиям) взяла на себя машина и таким образом стала самодостаточной (в смысле решения инженерной задачи).
У меня есть гипотеза (которую я проверяю, строя макетики), что инженер всегда пользуется одним единственным методом для выявления признаков, хотя в зависимости от контекста может называть его разными именами. Этот метод - связывание. Связь настолько многогранный, универсальный и при этом элементарный метод, что я пока вижу в нём "золотую жилу". Например, сейчас я пытаюсь построить (связать из частей) макетик, который будет выделять крупные элементы буквы путём связывания/развязывания точек буквы.
Если ты считаешь что это всё лишено смысла, хотелось бы услышать конкретные аргументы. Может и вправду я трачу время впустую или изобретаю самокат.
Поделиться1142009-08-21 00:03:42
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
Prosolver написал(а):
Если ты считаешь что это всё лишено смысла
всё лишено смысла, поэтому не имеет смысла использовать понятие "смысл"...
связность - это хорошая вещь...
сводить мышление к поиску связности не очень продуктивно... мышление - богаче...
имитация физики не поможет выявить эту связность,
поскольку сначала ты должен ее сформулировать на языке геометрии...
заниматься имитацией без четкой (формальной) формулировки - это симпатическая магия
или шаманские пляски...
см: http://ru.wikipedia.org/wiki/ Симпатическая_магия
http://ru.wikipedia.org/wiki/ Шаманизм
Поделиться1152009-08-21 00:29:00
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Egg написал(а):
сначала ты должен ее сформулировать на языке геометрии...
Я проверяю гипотезу, что язык геометрии - универсален. И меня можно будет в итоге из цепи исключить.
Egg написал(а):
заниматься имитацией без четкой (формальной) формулировки - это симпатическая магия или шаманские пляски...
1. У меня есть достаточно чёткая формулировка для узкой конкретной задачи, и я её приводил не раз, а именно: выделять крупные элементы буквы путём разбивания модели физической буквы (например, каменной) об стену. И, потом, насколько я помню: "точных описаний вообще не бывает..."
2. Я предпочитаю называть это экспериментами.
Поделиться1162009-08-21 00:37:09
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
не бывает точных онтологий ( см: http://ru.wikipedia.org/wiki/ Онтология),
а если ты хочешь, что-то обработать компьютером, ты должен сформулировать это на языке
данных... и такое описание будет формальным...
Prosolver написал(а):
выделять крупные элементы буквы путём разбивания модели физической буквы (например, каменной) об стену.
ноукоммент...
Поделиться1172009-08-21 03:10:20
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
Prosolver:
Наверно можно так настроить и запустить группу связанных шариков, что один из них нарисует слово.
Поделиться1182009-08-21 08:24:55
- Активный участник
- Откуда: CU, USA
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 1102
- Уважение: [+2/-1]
- Позитив: [+8/-1]
- Провел на форуме:
7 дней 7 часов - Последний визит:
2025-02-02 18:13:51
NO написал(а):
что один из них нарисует слово.
это уже будет обратная задача...
Поделиться1192009-08-21 15:34:26
- Активный участник
- Зарегистрирован: 2009-08-05
- Приглашений: 0
- Сообщений: 77
- Уважение: [+2/-0]
- Позитив: [+0/-0]
- Провел на форуме:
20 часов 46 минут - Последний визит:
2022-06-17 00:44:14
Egg написал(а):
"...для понимания энергии есть такой пример, точнее вопрос, почему камень, брошенный в лист бумаги, обладающий одной энергией просто отбрасывает ее, а при другой энергии - рвет ее, проделывая дыру, с которой Организм бумаги уже не может справиться?
И у меня только одно осмысленное предположение - из-за того, что Организм бумаги не может справиться с большей энергией, энергией, которую он не в состоянии усвоить, перевести ее в коммуникационные процессы своего устройства. Это настолько просто, что дальше некуда."
scrambled-egg-s.blogspot.com/search/label/энергия
Это мысль Эгг'а, в своё время, повергла меня в состояние безусловного согласия.
Если в ней доопределить термин "коммуникационные процессы" как "обмен квантами" то получаем в чистом виде продвигаемую мной идеологию связи.
NO написал(а):
Наверно можно так настроить и запустить группу связанных шариков, что один из них нарисует слово
NO зрит в корень! Конечно, подобные эксперименты запланированы. Я хочу научить компьютер анализировать буквы с целью их синтеза (а в дальнейшем - синтеза в контексте распознавания).
___________
С учётом идей предыдущего макета собран следующий макет, который демонстрирует принцип целостности и её разрушения.
Макет работает следующим образом.
1. Нарисованное или загруженное изображение подвергается рекурсивной процедуре разбиения на квадраты.
2. Между всеми квадратами высчитывается и запоминается начальное расстояние.
3. Каждому квадрату сообщается энергия, с расчётом, чтобы все они синхронно двигались к правому краю картинки - стенке.
4. Для каждой пары квадратов моделируется связь. В случае разлёта квадратов (>1 пиксела), относительно начального расстояния, они притягиваются, в случае сближения - отталкиваются.
При соударении буквы со стенкой видно как энергия удара волнообразно распредляется по всей букве, переходя в локальные взаимодействия ("коммуникационные процессы") между элементами. Интересно наблюдать за разрушением огромных букв (шрифт ~ 150).
В данном макете просчитываются связи каждого квадратика с каждым, т.е. буква получается полносвязная. Планирую так настроить модель, чтобы связанными оказывались только близкорасположенные квадраты (в некотором радиусе). И в дальнейшем добиться эффекта разлома буквы по "слабым" местам - уголкам, разрывам, утоньшениям.
Поделиться1202009-08-21 15:48:23
- Активный участник
- Зарегистрирован: 2009-08-03
- Приглашений: 0
- Сообщений: 454
- Уважение: [+5/-0]
- Позитив: [+8/-1]
- Провел на форуме:
5 дней 7 часов - Последний визит:
2012-08-20 09:25:48
обратная, при том, что задача движения трех тел уже не решаема
основная у меня пока сложилась как "построить из массива текстов недетерминированный автомат", такой хищный словарь, признак за признаком откусывающий картинку и при этом из страшного клубка вытягивающийся в одну линию где распознанное слово в голове, а остальное где-то там. При этом употребить всю картинку он должен за кратчайше время.
Отредактировано NO (2009-08-21 15:48:45)